数ヶ月の遅延と多くの憶測を経て、DeepSeekはついに待望の DeepSeek-V4をリリースした。これは DeepSeek-V3(2024年12月)および DeepSeek-R1(2025年1月)以来となるメジャーバージョンアップモデルである。このリリースにより、DeepSeekファミリーは、現在のオープンモデルのトップを走る Kimi K2.6 や、わずか2日前に公開された新鋭の Xiaomi Mimo 2.5 といった強力なモデル群と完全に肩を並べる存在となった。
本記事では、公開されたテクニカルレポートを基に、単純なベンチマーク結果の比較にとどまらず、DeepSeek-V4がいかにして100万(1M)トークンという極限のコンテキスト長を効率的に処理しているのか、その根幹を成す「アーキテクチャの革新」に焦点を当てて詳細に解説する。
長大なコンテキストがもたらす課題と DeepSeek-V4 の概要
Large Language Model (LLM) の応用範囲が拡大するにつれ、複雑な法的文書の分析、長大な論文の要約、あるいは巨大なコードベースの理解など、極めて長いテキスト系列を処理する能力への需要が急増している。しかしながら、従来の Transformer が採用する Attention 機構は、系列長に対して計算量が二次関数的に増加(\(O(N^2)\))するという根本的なボトルネックを抱えており、超長文のコンテキスト処理は計算コストおよびメモリ消費の観点から非現実的であった。
DeepSeek-V4 シリーズは、革新的なアーキテクチャ設計と最適化戦略によってこの課題に真っ向から取り組んでいる。今回発表されたのは、以下の2つの Mixture-of-Experts (MoE) モデルである。
- DeepSeek-V4-Pro: 1.6Tの総パラメータ数(トークンあたり49Bがアクティブ)を誇る巨大モデル。高度な推論と包括的なタスク処理能力を追求して設計されている。
- DeepSeek-V4-Flash: 284Bの総パラメータ数(トークンあたり13Bがアクティブ)を持つ、よりパラメータ効率の高いモデル。速度とコストパフォーマンスに最適化されている。
両モデルの最大の特徴は、驚異的な 100万トークンのコンテキスト長 をネイティブにサポートしている点である。これを可能にしたアーキテクチャ上のブレイクスルーを順に見ていこう。
コンテキストの壁を突破するハイブリッド Attention 機構
DeepSeek-V4 の中核的なイノベーションは、Compressed Sparse Attention (CSA) と Heavily Compressed Attention (HCA) を組み合わせたハイブリッド Attention アーキテクチャの採用にある。これにより、計算 FLOPs と KV cache のサイズを劇的に削減している。
Compressed Sparse Attention (CSA)
CSA は、KV cache を系列次元に沿って圧縮した上で、スパースな(疎な)Attention を適用するアプローチである。
- トークンレベルの圧縮: まず、隣接する \(m\) 個のトークンの KV cache を1つのエントリに圧縮する。これにより、実質的な系列長は \(1/m\) に縮小される。
- インデクサーによる動的選択: 圧縮された KV エントリに対して、各 Query トークンは軽量なインデクサー(Lightning Indexer)を用いて関連度スコアを計算する。そして、Top-\(k\) セレクタにより、スコアの高い \(k\) 個の圧縮 KV エントリのみを選択する(DeepSeek Sparse Attention; DSA)。
- Shared Key-Value MQA: 選択された \(k\) 個のエントリに対して Multi-Query Attention (MQA) を実行し、最終的な出力を得る。
Heavily Compressed Attention (HCA)
一方の HCA は、スパース化を行わない代わりに、さらにアグレッシブな圧縮を行う層である。ここでは \(m' \gg m\) となるような大きなウィンドウサイズ \(m'\) を用いて KV cache を圧縮する。系列全体の大局的なコンテキストを極めて低い計算コストで Dense(密)に捉える役割を果たす。
DeepSeek-V4 では、これら CSA と HCA を Transformer ブロック間でインターリーブ(交互に配置)させている。さらに、局所的な微細な依存関係を失わないよう、直近の一定数のトークンに対しては圧縮を行わずにアテンションを計算する Sliding Window Attention (SWA) のブランチも併用している。
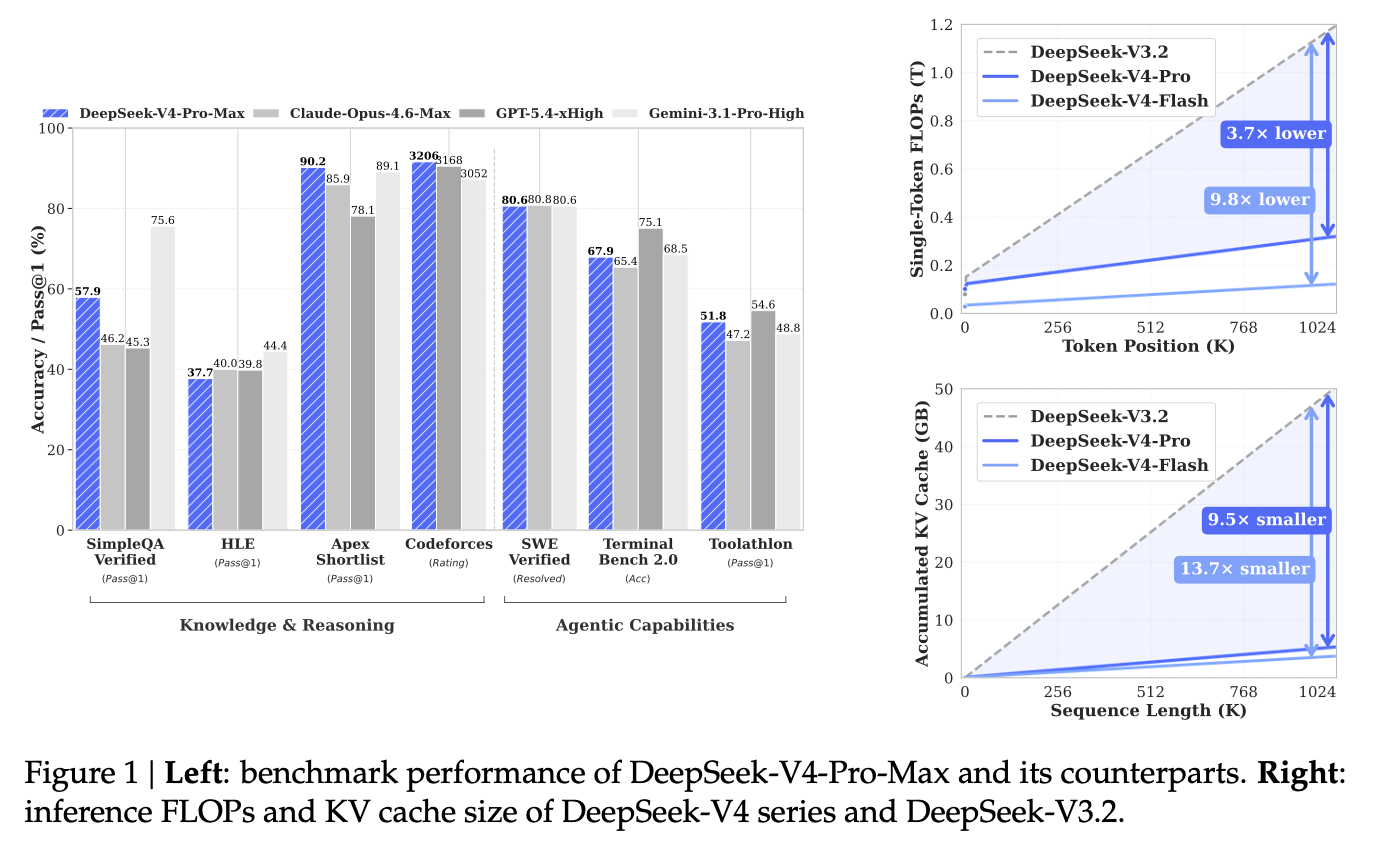
このハイブリッド設計の結果、1Mトークンのコンテキスト設定において、巨大な DeepSeek-V4-Pro でさえ、前世代の DeepSeek-V3.2 と比較して推論 FLOPs をわずか 27%、KV cache サイズを 10% にまで抑え込むことに成功している。
表現力と学習の安定性を両立する mHC (Manifold-Constrained Hyper-Connections)
モデルの深さを増すにつれて、Transformer ブロック間の残差接続(Residual Connections)における信号の減衰や数値的不安定性が顕著になる。近年、残差ストリームの幅を広げることでモデルの表現力を高める Hyper-Connections (HC) が提案されているが、層を深く重ねると学習が不安定になるという課題があった。
DeepSeek-V4 は、この問題に対して Manifold-Constrained Hyper-Connections (mHC) を導入している。
通常の HC における残差マッピング行列 \(B_l\) は、制約のないパラメータとして学習される。対して mHC では、この行列 \(B_l\) を二重確率行列(Doubly Stochastic Matrices、各行および各列の和が1となる非負行列)の多様体 \(\mathcal{M}\) に制約する。具体的には、Sinkhorn-Knopp アルゴリズムを用いて、学習プロセス中に行列をこの多様体へと射影している。
\[ \mathcal{M} := \left\{ M \in \mathbb{R}^{n \times n} \mid M \mathbf{1}_n = \mathbf{1}_n, \mathbf{1}_n^T M = \mathbf{1}_n^T, M \ge 0 \right\} \]
この数学的な制約により、変換行列のスペクトルノルムが厳密に 1 以下にバウンドされる。結果として、残差変換が非拡張的(non-expansive)な写像となり、順伝播および誤差逆伝播における極端な値の発散を防ぐことができる。これにより、高い表現力を維持したまま、超大規模モデルにおける深い層の学習安定性が飛躍的に向上した。
大規模 MoE モデルを支える Muon Optimizer とインフラストラクチャ技術
アーキテクチャの革新だけでなく、モデルを実際に訓練し、推論させるための基盤技術にも多大な進化が見られる。
Muon Optimizer の採用
LLM の学習においては、長らく AdamW が標準的なオプティマイザとして君臨してきたが、DeepSeek-V4 では隠れ層の重み更新に Muon Optimizer を採用している。最近、Kimi K2 シリーズや GLM-5 などの最先端オープンモデルの学習においてもその有効性が実証されているこの手法は、高次(Higher-order)の最適化アプローチの一種である。
Muon は、運動量(Momentum)バッファの蓄積に加え、Newton-Schulz イテレーションを用いたハイブリッドな直交化ステップを組み込んでいる。これにより、AdamW と比較して収束が速く、かつ大規模なパラメーター空間における学習の安定性が高い。分散学習時には通信ボトルネックが懸念される手法であるが、DeepSeek チームは ZeRO ベースの並列化戦略と組み合わせた独自のスケジューリングにより、スループットの低下を最小限に抑えつつスケーリングを可能にしている。
限界を押し広げるインフラストラクチャの最適化
さらに、以下のような多数のエンジニアリング上のブレイクスルーが実装されている。
- Expert Parallelism における通信と計算のオーバーラップ: MoE モデル特有の Expert Parallelism (EP) において、トークンの Dispatch および Combine の通信処理と、実際の計算(Linear 投影など)をきめ細かくオーバーラップさせる単一のメガカーネルを開発した。これにより、ネットワーク帯域幅への依存を減らし、エンドツーエンドのパフォーマンスを最大化している。
- TileLang による柔軟なカーネル開発: 複雑なハイブリッド Attention 機構や mHC の実装にあたり、実行時効率と開発の生産性を両立する Domain-Specific Language (DSL) である TileLang を採用している。
- 決定論的カーネルの徹底: 非同期処理に伴う非決定性を排除し、ビットレベルでの再現性を保証する高パフォーマンスなカーネルライブラリを構築することで、学習時のデバッグや Post-Training における挙動の一貫性を担保している。
- FP4 Quantization-Aware Training (QAT): MoE のエキスパート重みや、CSA におけるインデクサーの QK パスに対して FP4(4ビット浮動小数点)量子化を適用。学習段階からこの量子化のノイズを考慮する QAT を導入することで、モデルの品質を損なうことなく、推論時のメモリ消費と計算負荷を劇的に削減している。
まとめ
DeepSeek-V4 は、単一のモジュールの改良にとどまらず、Attention 機構のハイブリッド化(CSA / HCA)、残差接続の幾何学的制約(mHC)、高度な最適化アルゴリズム(Muon)、そして低レベルのカーネル最適化に至るまで、フルスタックのイノベーションを結集したモデルである。
32兆(32T)トークン以上という膨大なデータセットで事前学習され、徹底した Post-Training を経た DeepSeek-V4-Pro-Max は、知識、推論、そして長コンテキストタスクにおいてオープンモデルの新たな State-of-the-Art を打ち立て、先行するプロプライエタリモデルの性能に肉薄している。
100万トークンを効率的に処理できるという事実は、単に「長い文章が読める」という以上の意味を持つ。これは、膨大なコードベース全体を俯瞰したリファクタリング、複数ドキュメントを横断する複雑なマルチステップ推論、そして長期間にわたってコンテキストを維持し続ける高度なエージェント(Agentic AI)の構築など、新たな AI パラダイムへの扉を開くものである。オンライン学習や Test-Time Scaling のさらなる拡張といった将来の探求においても、DeepSeek-V4 のアーキテクチャはその堅牢な基盤となるだろう。
モデルのチェックポイントは Hugging Face にて公開されている。オープンモデルの進化がどこまでプロプライエタリの壁を押し崩していくのか、今後の展開から目が離せない。