2026年1月、DeepSeekの研究チーム(DeepSeek-AI)は、Large Language Model (LLM) のアーキテクチャにおける新たなパラダイムを提唱する論文「Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models」を発表した。
これまでのLLMのスケーリング則は、主にMixture-of-Experts (MoE) による「条件付き計算(Conditional Computation)」が牽引してきた。しかし、本論文はそこに「条件付きメモリ(Conditional Memory)」という新たな軸を導入することで、モデルの効率と性能を劇的に向上させる手法「Engram」を提案している。
本記事では、Engramの基本概念からアーキテクチャの詳細、そしてなぜこの構造が推論能力やシステム効率を向上させるのかについて、論文の内容に基づき技術的に深掘りして解説する。
1. Transformerが抱える「検索」の課題
現在のTransformerベースのLLMは、膨大な知識を保持しているが、その知識へのアクセス方法には本質的な非効率性が存在する。
論文では、既存のモデルが「知識の検索(Retrieval)を、高価な計算(Computation)によってシミュレートしている」と指摘している。例えば、「Alexander the Great(アレクサンドロス大王)」というエンティティを認識する場合、Transformerは複数のAttention層とFFN(Feed-Forward Networks)を経て、文脈からその意味表現を動的に再構築する必要がある。これは、静的なルックアップテーブルがあれば\(O(1)\)で済むはずの処理に、貴重な計算リソースを浪費していることを意味する。
DeepSeekの研究チームは、この「計算によるシミュレーション」を「条件付きメモリによるルックアップ」に置き換えることで、計算資源をより高度な推論(Reasoning)に集中させるべきだと提唱している。
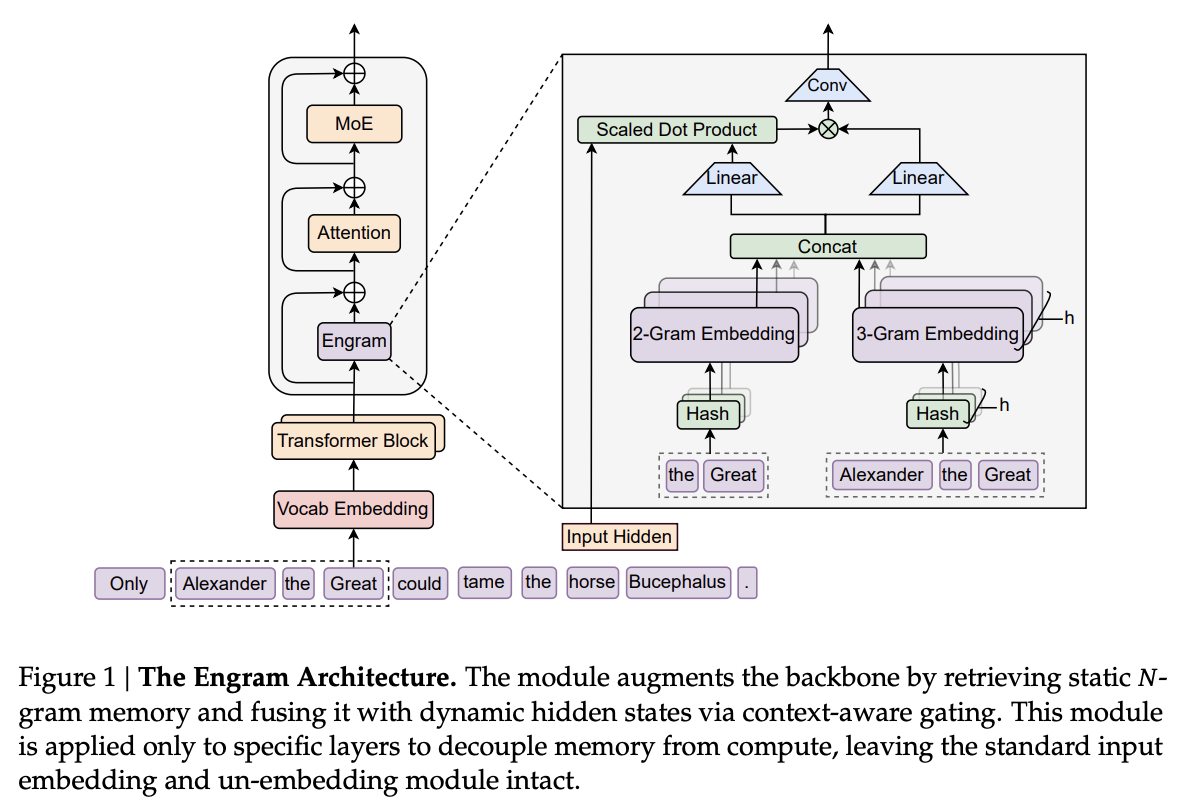
2. Engramアーキテクチャ:N-gramの現代的再解釈
Engramは、古典的なNLP技術である\(N\)-gramモデルの概念を現代的なニューラルネットワークに統合したモジュールである。その中核となるのは、入力トークン列に基づいて静的な埋め込みベクトルを定数時間で検索し、それを文脈に応じて動的に統合する仕組みだ。
2.1 スパース検索とハッシュ化
Engramの第一段階は、トークン列からパターンを検索することである。しかし、単純な\(N\)-gramテーブルは語彙数に対して爆発的に増大するため、以下の工夫が凝らされている。
- Tokenizer Compression (トークナイザ圧縮): 通常のサブワードトークナイザでは、“Apple”と” apple”(スペースあり)は別のIDを持つ。Engramでは、これらを正規化して同一視する射影層を導入し、実効的な語彙サイズを約23%削減することで、意味的な密度を高めている。
- Multi-Head Hashing: 全ての\(N\)-gramを保持するのは不可能なため、ハッシュ化を採用している。衝突(Collision)の影響を緩和するため、\(K\)個の異なるハッシュヘッドを使用し、複数の埋め込みテーブルからベクトルを検索して連結する。
\[ \mathbf{e}_t = \Concat_{n=2}^{N} \Concat_{k=1}^{K} \mathbf{e}_{t,n,k} \]
ここで、\(\mathbf{e}_{t,n,k}\)は、位置\(t\)における\(n\)-gramに対応する\(k\)番目のハッシュヘッドから取得された埋め込みベクトルである。
2.2 Context-Aware Gating (文脈認識ゲーティング)
単に\(N\)-gram埋め込みを取得しただけでは、文脈を無視した静的な情報に過ぎない(例:「bank」が「銀行」か「土手」か区別できない)。そこでEngramは、現在の隠れ状態\(\mathbf{h}_t\)を用いたゲーティング機構を導入している。
取得されたメモリベクトル\(\mathbf{e}_t\)は、Key (\(\mathbf{k}_t\)) とValue (\(\mathbf{v}_t\)) に射影され、現在の隠れ状態(Queryとして機能)との内積によってゲート値\(\alpha_t\)が計算される。
\[ \alpha_t = \sigma \left( \frac{\text{RMSNorm}(\mathbf{h}_t)^\top \text{RMSNorm}(\mathbf{k}_t)}{\sqrt{d}} \right) \]
\[ \tilde{\mathbf{v}}_t = \alpha_t \cdot \mathbf{v}_t \]
この\(\alpha_t\)により、現在の文脈に合致する知識のみが取り込まれ、ノイズ(ハッシュ衝突や無関係な\(N\)-gram)は抑制される。この設計はAttention機構に似ているが、動的なトークン間の相互作用ではなく、静的メモリへのアクセスを行う点が異なる。
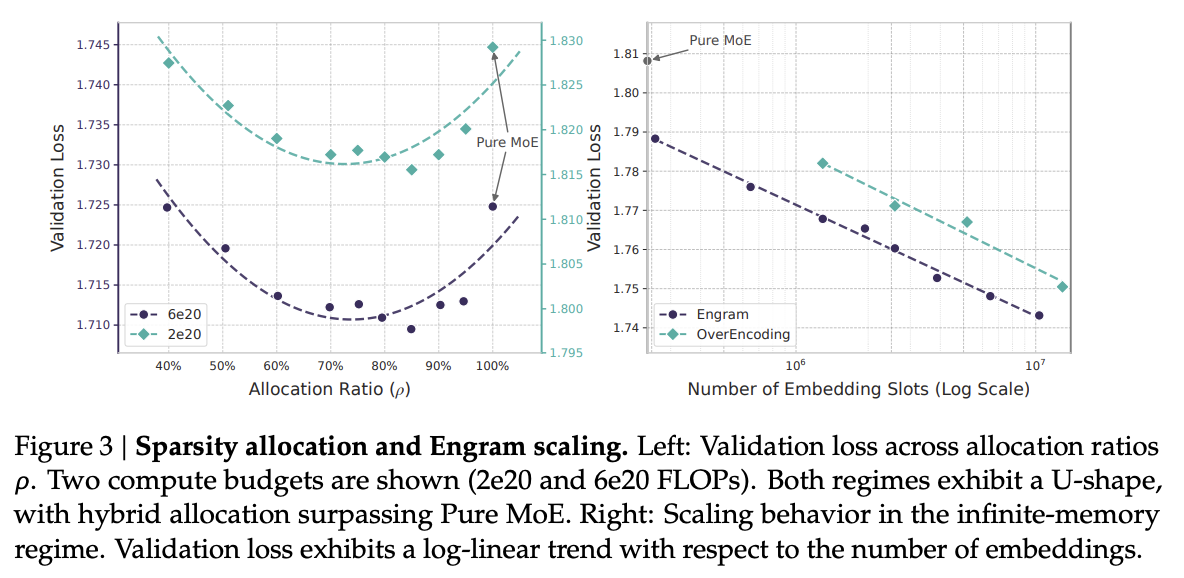
3. Sparsity Allocation:計算とメモリの最適配分
本研究の最も重要な貢献の一つは、「Sparsity Allocation(スパース性の配分)」という問題を定式化した点にある。
MoEモデルにおいて、パラメータ総数と計算量(FLOPs)を固定した場合、リソースを「MoEのエキスパート(計算)」に割くべきか、「Engramのメモリスロット(記憶)」に割くべきか?
U字型のスケーリング則
実験の結果、このトレードオフには明確なU字型のスケーリング則が存在することが判明した。
- Pure MoE (\(\rho=100\%\)): 全てのリソースをMoEに割くと、静的なパターンの再構築に計算能力が奪われ、非効率となる。
- Optimal Mix (\(\rho \approx 75\%-80\%\)): スパースパラメータの約20〜25%をEngramメモリに割り当て、残りをMoEエキスパートに割り当てる構成が、損失(Loss)を最小化する。
つまり、MoEとEngramは競合するものではなく、相互補完的な関係にある。MoEは動的な論理・推論を担当し、Engramは静的な知識・パターンのルックアップを担当することで、全体としての効率が最大化されるのである。
4. Engram-27Bの性能とメカニズム分析
この配分則に基づいて構築されたEngram-27Bは、同等のパラメータ数・FLOPsを持つMoEベースライン(MoE-27B)と比較して、驚くべき結果を示した。
4.1 知識タスクを超えた推論能力の向上
直感的には、メモリの追加は「知識集約型タスク(MMLU, TriviaQAなど)」に効くと予想される。実際、MMLUで+3.4pt、CMMLUで+4.0ptの向上が見られた。
しかし、より興味深いのは、一般的な推論(Reasoning)、コード、数学といったタスクにおいても大幅な向上が確認された点である。
- BBH (Big-Bench Hard): +5.0
- ARC-Challenge: +3.7
- HumanEval (Code): +3.0
- MATH: +2.4
なぜ静的なメモリが推論能力を向上させるのか?
4.2 「実効的な深さ」の向上とAttentionの解放
論文では、LogitLensとCKA (Centered Kernel Alignment) を用いた解析により、このメカニズムを解明している。
- 浅い層での予測収束: Engramを導入すると、モデルの浅い層(初期レイヤー)における予測分布が、最終的な出力分布に急速に近づくことが確認された。
- 実効的な深さの深化: CKAによる類似度解析では、Engramモデルの「層5」の表現が、MoEベースラインの「層12」の表現に相当することが示された。
これは、Engramが初期レイヤーにおける「静的な知識の再構築」という負荷を肩代わり(オフロード)していることを示唆している。結果として、Transformerの層(特にAttention機構)は、単純な知識検索から解放され、より複雑な推論や長距離の文脈理解に専念できるようになる。
実際、長文脈タスク(Long Context)においても、Engram-27BはRULERやNIAH(Needle In A Haystack)ベンチマークでベースラインを圧倒しており(Multi-Query NIAH: 84.2 \(\to\) 97.0)、Attentionの容量がグローバルな文脈処理のために温存されていることが裏付けられている。
5. インフラストラクチャを意識した効率性
Engramは、純粋なモデル性能だけでなく、システム実装の観点からも極めて合理的に設計されている。
計算とメモリの分離 (Decoupling)
MoEのルーティングは実行時の隠れ状態に依存するため、事前の予測が難しく、通信と計算のオーバーラップが複雑になる。対して、Engramのアクセス先は入力トークン列のみによって決定(決定的)される。
これにより、以下のシステム最適化が可能になる:
- プリフェッチ: 推論時、実際に層の計算が始まる前に、CPU(ホストメモリ)から必要な埋め込みベクトルをGPUに転送(Prefetch)できる。
- 通信の隠蔽: 前段のTransformerブロックの計算中に、次段のEngramのメモリ転送を行うことで、通信レイテンシをほぼ完全に隠蔽できる。
実験では、100B(1000億)パラメータ規模の巨大なEngramテーブルをホストメモリ(CPU側)に配置し、推論を行った場合でも、スループットの低下は3%未満に抑えられた。これは、GPUメモリ(HBM)の制約を超えて、モデルの「記憶容量」を実質的に無限にスケールさせることが可能であることを示している。
まとめ
DeepSeekによる「Engram」は、LLMの設計において長らく支配的だった「全てをニューラルネットワークの重みで表現する」というアプローチに対し、「条件付きメモリ」という古典的かつ新しいプリミティブを再導入した。
- 構造的補完性: MoE(動的計算)とEngram(静的メモリ)は最適なバランスで共存すべきである。
- 推論能力への寄与: 単なる知識ベースではなく、初期層の負荷をオフロードすることで、モデル全体の実効的な深さと推論能力を向上させる。
- システム優位性: 決定的なアクセスパターンにより、GPUメモリの壁を超えたスケーリングを可能にする。
今後、数千億、数兆パラメータを目指す次世代のスパースモデルにおいて、Engramのような「計算と記憶の分離」は、不可欠な標準技術となっていく可能性が高い。
参考文献
- Cheng, X., et al. (2026). “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”. arXiv preprint arXiv:2601.07372.
- DeepSeek-AI. (2024). DeepSeek-V3 Technical Report.
- Xie, Z., et al. (2025). mHC: Manifold-Constrained Hyper-Connections.