近年、Large Language Model (LLM) のコンテキストウィンドウは拡大の一途を辿っている。100万トークン、あるいはそれ以上を処理できるモデルが登場しているが、そこには依然として「有効なコンテキスト長」と「Context Rot(コンテキストの腐敗)」という根深い問題が存在する。単にウィンドウを広げるだけでは、モデルは情報の海に溺れ、推論能力は著しく低下してしまうのだ。
MIT CSAILの研究チームらが発表した画期的な論文『Recursive Language Models (RLMs)』は、この問題に対して、モデルのアーキテクチャを変えるのではなく、推論戦略(Inference Strategy)を根本から変えるアプローチを提案している。
また、AI研究機関であるPrime Intellectも、このRecursive Language Modelsを「2026年のパラダイム」として位置づけており、次世代の長文脈処理の標準となる可能性を秘めている。本記事では、このRLMの基本概念から、その圧倒的なパフォーマンス、そして将来の可能性までを詳細に解説する。
なぜ「長いコンテキスト」は難しいのか?
LLMが数百万トークンを入力として受け取れるようになったとしても、それは「すべての情報を正しく理解し、推論できる」ことを意味しない。
- Context Rot(コンテキストの腐敗): 入力長が増加するにつれて、LLMの性能が劣化する現象。特に、関連情報がコンテキストの中間に位置する場合に取得に失敗する「Lost in the Middle」問題が知られている。
- 計算量の爆発: TransformerのAttention機構は、入力長に対して二乗の計算量(Quadratic complexity)を要する場合が多く、超長文脈の処理は計算コスト的に極めて重い。
- タスクの複雑性: 単純な情報の検索(Needle-in-a-Haystack)であれば現在のモデルでも対応可能だが、文書全体に散らばる情報を集約・変換し、推論するような高密度なタスク(例:OOLONGベンチマーク)では、最先端のフロンティアモデル(GPT-5やQwen3-Coderなど)であっても、コンテキストが長くなると壊滅的な性能低下を示す。
Recursive Language Models (RLM) の基本原理
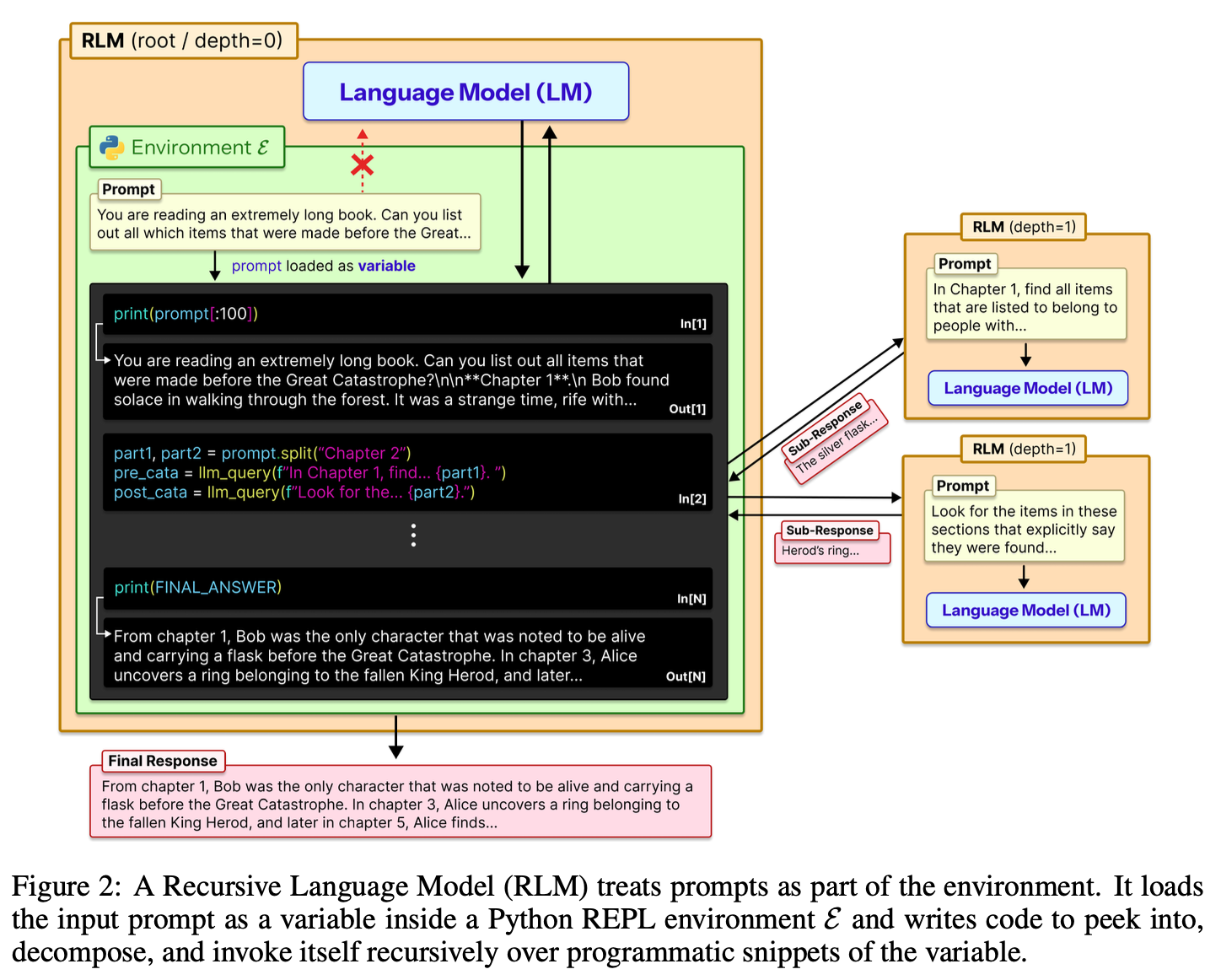
Recursive Language Models (RLM) の核心的なアイデアは、「長いプロンプトをLLMへの入力として扱わず、外部環境(Environment)として扱う」という点にある。
従来の手法では、プロンプト \(P\) を直接ニューラルネットワークに入力していた(例:\(P \to \text{LLM} \to \text{Answer}\))。しかしRLMでは、プロンプトをPythonのREPL(Read-Eval-Print Loop)環境内の変数として保持させる。
動作の仕組み:Out-of-Core アルゴリズムからの着想
RLMのアプローチは、メインメモリに入りきらない巨大なデータを処理するための「Out-of-Core アルゴリズム(外部記憶アルゴリズム)」に着想を得ている。RLMにおけるLLMは、小さなメインメモリ(自身のコンテキストウィンドウ)を持つCPUのような役割を果たし、巨大なプロンプト(外部ディスク)に対して以下のようなプログラム的な対話を行う。
Peek and Decompose(覗き見と分解): LLMはREPL環境を通じて、プロンプト全体を一度に読み込むのではなく、「最初の1000行」や「特定のキーワードを含む部分」といった形で、データを部分的に検査・分解するコードを記述・実行する。
Recursive Self-Calling(再帰的な自己呼び出し): ここが最大の特徴である。分解されたデータの断片(スニペット)に対して、LLMは自分自身(またはサブLLM)を関数として再帰的に呼び出す。 例えば、「データの前半部分を要約せよ」というサブタスクを生成し、その結果を変数として保持し、次の処理に利用する。これにより、階層的な情報の処理が可能となる。
Observe Side Effects(副作用の観測): 再帰呼び出しやコード実行の結果を観測し、十分な情報が集まるまでこのプロセスをループさせる。
このプロセスにより、RLMは理論上、無限長のコンテキストを扱うことが可能になる。実際に、研究では1,000万トークンを超える入力の処理に成功している。
圧倒的なパフォーマンスとコスト効率
論文では、RLMの有効性を検証するために、GPT-5およびQwen3-Coderを用いた広範な実験が行われている。比較対象には、ベースとなるLLMへの直接入力、RAG(検索拡張生成)、CodeAct、そして要約エージェントなどが含まれる。
1. 複雑な推論タスクでの圧勝
特に注目すべきは、情報の密度が高く、推論の複雑さが入力長に対して二次関数的に増加するタスク「OOLONG-Pairs」での結果である。
- Base LLM (GPT-5 / Qwen3): 入力長が増えるとF1スコアはほぼ0%近くまで低下。情報の洪水の中で推論が破綻する。
- RLM: ベースモデルが手も足も出ない状況下で、一貫して高いF1スコアを維持。
これは、RLMが巨大な問題を「管理可能なサブ問題」に分割し、再帰的に解決することで、Transformer固有の注意機構の限界を突破していることを示している。
2. Deep Research能力
複数の文書にまたがる推論を要する「BrowseComp-Plus」ベンチマークにおいても、RLMは傑出した性能を示した。従来のRAGが「検索してコンテキストに詰める」だけなのに対し、RLMはプログラム的に文書間をナビゲートし、必要な情報を能動的に取得・統合できるためである。
3. コストパフォーマンス
直感的には、何度もLLMを呼び出すRLMは高コストに思えるかもしれない。しかし、驚くべきことに、RLMのクエリあたりのコストは、他の長文脈戦略(入力をすべて要約する手法など)と比較して同等、あるいはより安価であることが示された。 これは、RLMが必要な部分のみを選択的に読み込み(Selective Reading)、無関係なトークンを処理しないためである。
既存の長文脈手法との比較
現在主流となっている長文脈へのアプローチとRLMを比較すると、そのパラダイムシフトが明確になる。
| 手法 | アプローチ | 課題 |
|---|---|---|
| Context Window Scaling | モデル自体の入力可能トークン数を増やす(例:Gemini 1.5)。 | 有効コンテキスト長(Effective Context)の限界、計算コストの増大。 |
| RAG (Retrieval) | 関連するチャンクを検索し、コンテキストに挿入する。 | 検索漏れ、全体像の把握が困難、複雑な推論(Multi-hop)に弱い。 |
| Summarization / Compaction | 過去の情報を要約して圧縮する。 | 圧縮による情報の欠落(Lossy compression)。詳細な推論に必要な情報が消える。 |
| RLM (Recursive) | プロンプトを環境として扱い、コード実行と再帰呼び出しで探索する。 | 推論レイテンシ(逐次処理のため)、実装の複雑さ。 |
RLMは、LLMに「読む」能力だけでなく、「データを操作し、探索する」能力を与えることで、これらの課題を解決している。
課題と将来の展望
RLMは強力なソリューションであるが、論文ではいくつかの課題と将来の方向性についても言及されている。
- レイテンシと最適化: 現在の実装は同期的な再帰呼び出しを行っているため、実行時間が長くなる傾向がある。非同期処理(Asynchronous sub-calls)や並列化によって、大幅な高速化が見込まれる。
- RLMへの特化学習: 現状は汎用のLLMをRLMとして使用しているが、RLMの役割(ルートエージェントとしての振る舞いや、サブタスクの処理)に特化してモデルをトレーニングすることで、さらなる性能向上が期待される。
- 短い入力でのオーバーヘッド: 非常に短いプロンプトの場合、RLMのフレームワークを立ち上げるオーバーヘッドにより、ベースLLMを直接叩く方が効率的な場合がある。入力長に応じた使い分けが必要となるだろう。
結論:AIエージェントの自律性への道
Recursive Language Modelsは、単なる「長い文章が読める」技術ではない。これはLLMを、受動的なテキスト処理器から、巨大な情報環境を自律的に探索・処理する能動的な計算ユニットへと進化させるものである。
Prime Intellectが予測するように、2026年にはこの再帰的な処理モデルが、Deep Research、コードベースの解析、そして複雑なデータ分析における標準的なパラダイムとなる可能性が高い。我々は今、LLMが真に「文脈」を理解し始める転換点に立っているのかもしれない。
参考文献:
- Recursive Language Models. arXiv:2512.24601
- Prime Intellect Blog: Recursive Language Models