近年、Large Language Model (LLM) のスケールアップにおいて、Mixture-of-Experts (MoE) アーキテクチャの採用が標準的なアプローチとなりつつある。MoEモデルは条件付き計算(Conditional computation)により、Denseモデルと比較してパラメータ効率や推論速度の面で優位性を持つ。しかしながら、その巨大なモデルサイズゆえに、事前学習(Pre-training)や推論時のサービングにかかる計算コストおよびメモリ要件は依然として極めて高い。すべてのアクティブなExpertをメモリにロードする必要があるため、ハードウェアへの要求水準が跳ね上がるからである。
この課題に対処すべく、様々なモデル圧縮技術が研究されている。本稿では、大規模なMoEモデルの効率的な圧縮手法と最適化のメカニズムを体系的に調査した最新の論文「SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training」に基づき、その主要な発見と技術的ブレイクスルーについて解説する。
大規模MoEモデルの圧縮における課題
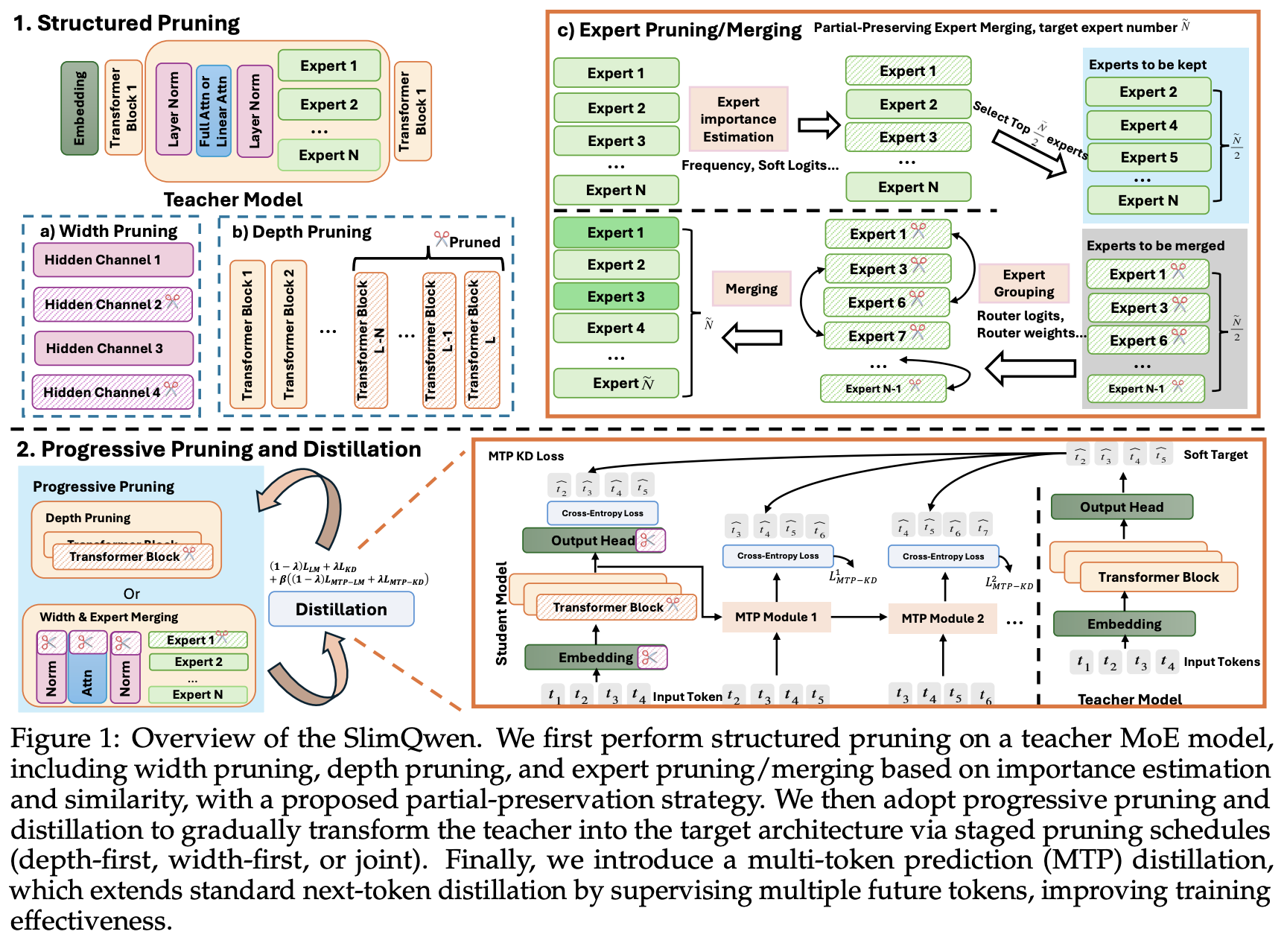
Denseモデルにおいては、ネットワーク全体から層(Layers)やアテンションヘッド(Attention heads)を削除する構造化枝刈り(Structured Pruning)や、巨大なTeacherモデルから小規模なStudentモデルへ知識を転移させる知識蒸留(Knowledge Distillation, KD)といった手法が一定の成功を収めてきた。
しかし、MoEアーキテクチャの圧縮には、これらに加えて「Expert」そのものを枝刈り、あるいは統合(Merging)できるという固有の次元が存在する。既存の研究では一度の操作(One-shot)によるエキスパート圧縮の評価は行われていたものの、大規模な継続事前学習(Continual Pre-training)を前提とした場合に、これらの圧縮手法がどのように機能するのかは未解明であった。
SlimQwenの研究チームは、このギャップを埋めるべく、大規模なMoE事前学習のコンテキストにおいて以下の3つの核心的な問いを立て、体系的な検証を行った。
- 初期化(Initialization): 事前学習済みのMoEモデルを枝刈りしたものは、同一のターゲットアーキテクチャを一から学習(Training from scratch)するよりも優れた初期化地点となるか?
- エキスパートの圧縮戦略(Expert Compression): エキスパートを圧縮する様々なアプローチは、継続事前学習後の最終的なパフォーマンスにどのような影響を与えるのか?
- 学習レシピ(Training Recipe): 圧縮による性能低下を回復させるための、最も効果的な学習戦略(目的関数やスケジュール)は何か?
枝刈り、蒸留、そして段階的スケジュール:SlimQwenの主要な発見
SlimQwenの論文は、広範な実験を通じて、MoEモデルの圧縮に関するいくつかの実践的かつ重要な知見を提示している。
1. 枝刈りによる強力な初期化(Pruning as a Strong Initializer)
Structured Pruningによるモデルの縮小が有効な初期化手法となるかを検証した結果、同じ学習バッチ・トークン数の予算下であっても、事前学習済みMoEモデルをターゲットアーキテクチャに枝刈りしたものは、一から学習したモデルのパフォーマンスを常に凌駕することが明らかとなった。汎用知識、推論、コーディングを含む様々なダウンストリームタスクにおいて一貫したスコア向上が見られ、損失関数(Loss)の収束も極めて早い。これは、枝刈りがタスクに不可欠な重み(知識)を効果的に保持し、極めて有益な初期パラメータとして機能することを示している。
2. エキスパート圧縮手法の収束と Partial-preservation 戦略
MoEアーキテクチャ特有の要素であるExpertの圧縮について、ルーターのロジットや発火頻度など、様々な基準を用いたOne-shotのエキスパート枝刈りおよびマージ手法の比較が行われた。驚くべきことに、数千億トークン規模の大規模な継続事前学習を経た後では、どの一段階の圧縮手法を採用しても、最終的なパフォーマンスに有意な差は生じないことが判明した。単一の手法がすべてのタスクで優位に立つことはなかったのである。
この観察結果と、事前学習されたExpertの特化(Specialization)を維持しつつ冗長性を削減する必要性に基づき、研究チームは 「Partial-preservation expert merging strategy(部分保存エキスパートマージ戦略)」 を提案している。 この戦略は、重要度の高い上位半分のターゲットExpertを「無傷で(Intact)」保持し、残りの下位Expertを保持されたベースExpertに対して類似度に基づいてマージするというシンプルなアプローチである。これにより、モデル表現の過度な均質化(Homogenization)を防ぎつつ効果的なパラメータの統合が可能となり、主要なベンチマーク全体で一貫した性能向上が確認された。
3. Knowledge Distillation と LM Loss の融合、および MTP Distillation の導入
圧縮されたモデルの性能を最適に回復させるための学習目的関数(Loss function)についても重要な知見が得られている。純粋な Knowledge Distillation (KD) 単独に依存するのではなく、標準的な Language Modeling (LM) Loss を線形減衰スケジュールで組み合わせたハイブリッドな目的関数が、特にMMLUなどの知識集約型のタスクにおいて優れた回復力を示した。
さらに本研究は、事前学習時の目的関数として Multi-Token Prediction (MTP) distillation を導入している。これは、単一の次トークン(Next-token)だけでなく、複数の未来のトークンに対するTeacherモデルの予測分布をStudentモデルに蒸留するパラダイムである。MTP KDの導入は、バックボーンモデルの学習ダイナミクスと表現品質を根本的に高めるだけでなく、推論時の Speculative Decoding(投機的デコード)におけるドラフトトークンの受容率(Acceptance rate)を大幅に向上させるという実用的な利点ももたらす。
4. 段階的な枝刈り(Progressive Pruning Schedules)の優位性
巨大なBaseモデルから小さなTargetモデルへの移行において、一度にすべての圧縮を行う(One-shot compression)のではなく、段階的にキャパシティを削減する Progressive Pruning の有効性が確認された。 研究では、Depth-first(深さ優先)、Width-first(幅優先)、Joint(同時並行)といった2段階の圧縮スケジュールが検証された。その結果、最終的なスパース性や総学習トークン数が同一であっても、段階的なアーキテクチャの縮小を行う戦略が一貫してOne-shotの圧縮を上回る成果を上げた。段階的なキャパシティの削減は、最適化の軌道(Optimization trajectory)をより滑らかにし、Teacherモデルからの知識転移における情報欠損を緩和する効果があると考えられる。
SlimQwenの実証:Qwen3-Nextの圧縮
これらの発見と提案手法を統合し、研究チームは実際に大規模モデルである「Qwen3-Next-80A3B」をベースとして圧縮を実行した。上記の手法(Partial-preservationマージ、Progressive Pruning、MTP KDを含むハイブリッド学習)を適用することで構築された「SlimQwen-23A2B」モデルは、約4倍という劇的な圧縮率を達成している。
結果として得られたこのコンパクトなモデルは、一般的な推論(BBH)、数学(GSM8K)、コーディング(EvalPlus)、および多言語ベンチマークを含む広範な評価において、極めて競争力のある性能を維持することに成功した。
結論と実世界へのインプリケーション
Large Language Model (LLM) の実世界におけるデプロイメントは、常にスケーラビリティとリソース制約のジレンマに直面している。モデルサイズが巨大化するほど、GPUなどのハードウェアにかかる運用コストやエネルギー消費は膨張し、リアルタイムアプリケーションに求められる低レイテンシの実現が困難となる。
DeepSeek-v2における Multi-head Latent Attention (MLA) の採用や、QMoEに代表される量子化フレームワークなど、MoEの効率性を高めるための研究は多岐にわたる。その中で、SlimQwenの論文は、「事前学習スケールにおけるMoE固有の構造化枝刈りと蒸留」 というアプローチに焦点を当て、実証的かつ実践的なガイドラインを確立した点で高く評価できる。
Initializationの優位性、Expert圧縮におけるPartial-preservationの重要性、MTP KDを利用した学習レシピ、そしてProgressive Pruningの恩恵。これらを深く理解し適用することで、我々はモデルの潜在能力を大きく損なうことなく、よりアクセスしやすく、コスト効率の高い強力な Mixture-of-Experts モデルを構築することが可能となる。SlimQwenが提示したフレームワークは、高度な生成AIを単一GPU環境などのより制約のある環境へデプロイするための、重要な技術的基盤となるだろう。